На 2-й конференции российских разработчиков разгорелся спор между разработчиками: какой из способов организации связей между таблицами является более оптимальным — метод «паука» или метод «якорей и буйков». Меня, как автора цикла статей, да и как аналитика в принципе, жутко заинтересовал этот вопрос.
Кратко опишу суть обоих методов.
1. Метод «паука».
Суть данного метода состоит в том, что центральным звеном всей базы данных является системная таблица Pro (или Pref). Она служит для организации связи между всеми таблицами с данными и таблицами настроек. В этом режиме организации связей каждая таблица «видит» каждую другую таблицу + таблицу настроек. Некоторые разработчики считают, что это ускоряет разработку макетов (лэйаутов) для доступа к данным.
2. Метод «якорей и буйков».
Суть следующего метода заключается в соблюдении следующего принципа: каждая таблица с данными представляет собой как бы отдельный модуль структуры. К ней, через связи мы подключаем остальные необходимые таблицы. При этом каждая таблица «видит» только необходимые таблицы с данными и логические копии таблицы настроек (при необходимости).
Рассмотрим объективно сравнительные характеристики двух данных методов построения связей между источниками данных. Сравнение произведем по двум характеристикам:
- быстрота разработки нового макета (лэйаута) данных
- быстродействие всей базы данных в принципе
Для выяснения указанных спорных вопросов мною была создана тестовая база данных для проверки обоих режимов реляций.
Метод «паука» был реализован следующей структурой:
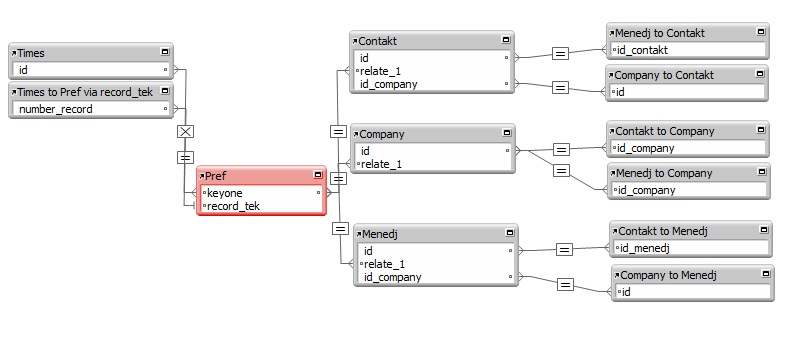
Соответственно, для анализа метода «якорей и буйков» структура базы была несколько преобразовано в соответствии с условиями метода:
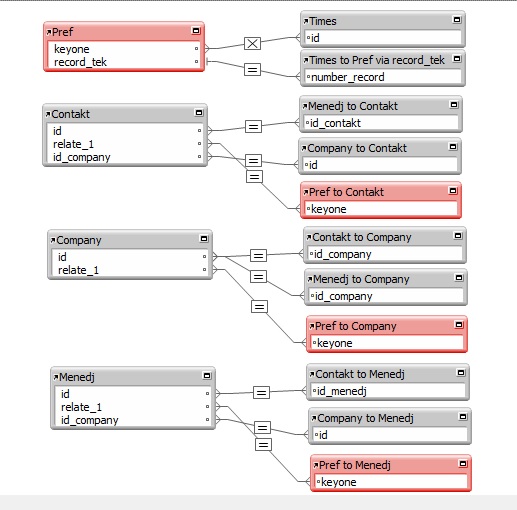
Сложную структуру данных создавать не стал, ограничился тремя таблицами данных и одна таблица, имитирующая таблицу настроек.
А) Для начала рассмотрим и сравним ситуацию с созданием и редактированием нового макета.
На первый взгляд метод «паука» имеет преимущество по данной позиции. При его использовании создание нового макета производится дублированием и переименованием текущего макета с данными. При этом не требуется переописание полей таблицы Pref.
При использовании метода «якорей и буйков» на каждом новом макете требуется переописание полей таблицы Pref (поскольку на каждом макете — это другая логическая таблица).
Но рассмотрим более подробно настройку макетов. Отметим в качестве преамбулы, что есть разница в выборе источника данных для полей макета. Посмотрим на окно выбора таблиц-источников данных для поля в первом и втором случаях.
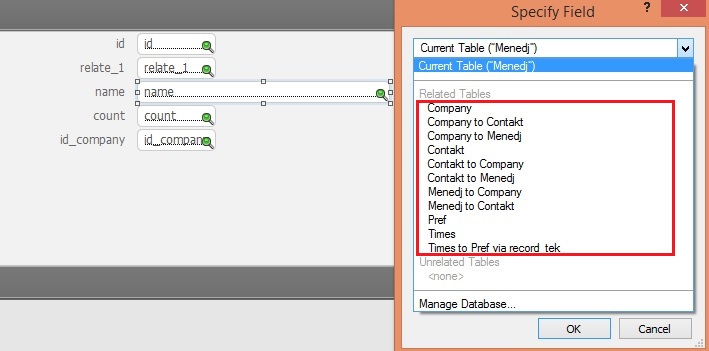
Для структуры типа «паук»
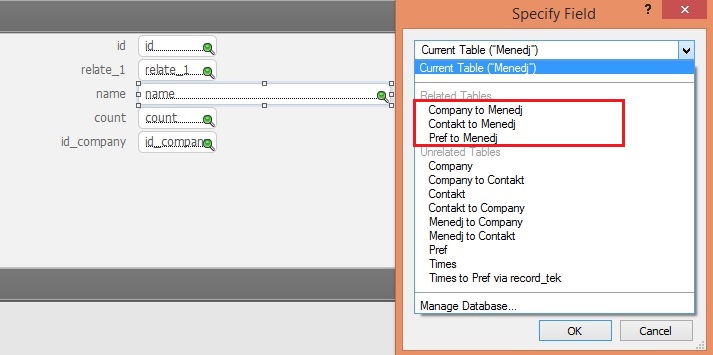
Для структуры типа «якори и буйки»
Из представленных изображений ясно видно, что список выбора таблиц для структуры «паук» примерно в 3-4 раза превышает список выбора для структуры «якори и буйки». Таким образом описание одного элемента данных (не интерфейса) занимает на несколько секунд больше из-за необходимости прокрутки.
Произведем вычисления, предположив, что у нас на макете в среднем 30 элементов данных и 10 элементов интерфейса. Можно сделать выводы:
- мы «теряем» на интерфейсных элементах примерно 5 сек. * 10 элем. = 50 сек (список выбора таблиц короткий)
- но, с другой стороны, мы приобретаем 5 сек. * 30 элем. = 150 сек.
- следовательно, «чистый» выигрыш составляет 100 сек. (около 2 минут).
Таким образом, мы выяснили, что в любом случае (т.к. практически всегда число элементов данных превышает число интерфейсных элементов) метод «якорей и буйков» оказывается более эффективным при разработке новых макетов.
Б) Рассмотрим второй спорный момент, что быстродействие обработки данных одинаково для обеих систем.
Поскольку структура базы была создана достаточно простой (что бывает чрезвычайно редко) для сравнения систем был разработан скрипт, имитирующий вычислительную нагрузку на базу данных. Мы в цикле сначала производим запись определенного числа записей в таблицы, а потом их удаляем. При этом производим засечку начального и конечного времени.
Приведу текст скрипта:

Далее мы запускаем данный алгоритм для числа записей от 2000 до 15000 с шагом 1000. Полученные результаты для обоих методов структуры связей записываем в таблицу. В результате в той же тестовой базе данных получаем таблицу и график:
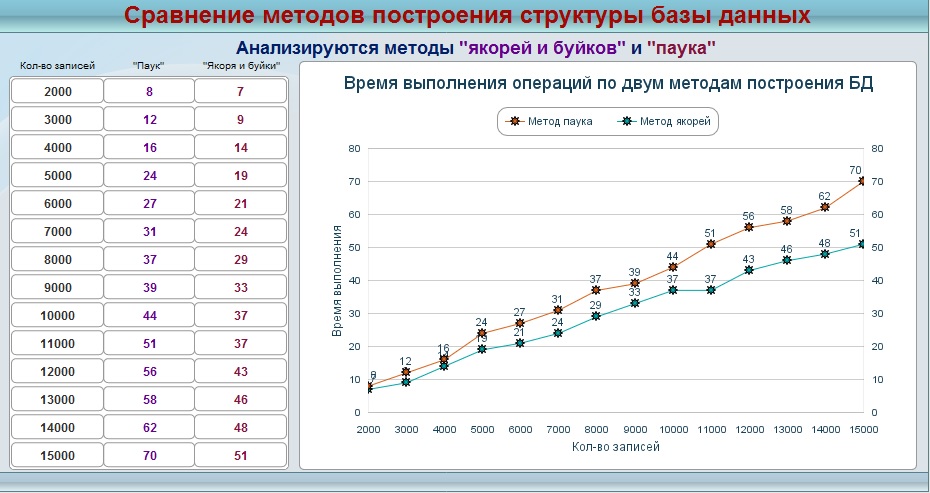
Немного проанализируем таблицу и полученный график. Явно заметно, что с увеличением числа обрабатываемых записей, разница во времени обработки увеличивается в геометрической прогрессии. Связано это с тем, что в любом случае при обработке записи производится анализ связей между таблицами. Конечно, разница в 5-6 связей заметна не будет. Но совсем другое дело, когда речь идет о разнице в 5-6 раз. Примерно можно прикинуть:
- в базе данных в 20 таблиц при методе «якорей и буйков» при обработке 1 записи анализируется примерно 10-15 связей
- в такой же таблице при методе «паук» анализируется примерно 90-100 связей
Таким образом, можно сделать вывод, что и по второй сравниваемой позиции метод «якорей и буйков» оказывается предпочтительней метода «паука».
На мой взгляд, метод «паука» может применяться для простых проектов, состоящих из 2-3 таблиц и не требующих больших вычислений.
В случае объемной разработки, для больших (более 10 таблиц) проектов, логично все же применение метода «якорей и буйков».